Vladimir Vuksan's Blog Documenting the systems and network infrastructure madness
- ENDPOINT needs to point to the Fastly endpoint for the region you want to use e.g
eu-central.object.fastlystorage.app - URL_STYLE needs to use
path
Using Fastly Object Storage with DuckDB
22 January 2025
DuckDB allows direct querying/importing of data from HTTP endpoints including S3 compatible storages. The httpfs extension currently lacks
direct support for Fastly Object Storage however as it is S3 compatible all you need to do is
modify the S3 type to support it. The only two changes are
For example I have a bucket in us-east region and my config looks as follows.
CREATE SECRET secret1 (
TYPE S3,
KEY_ID 'K******************',
SECRET '*******************************',
REGION 'us-east',
ENDPOINT 'us-east.object.fastlystorage.app',
URL_STYLE 'path'
);
After that’s done you can do things like
SELECT * FROM 's3://my-test-bucket/data.csv';
Raspberry Pi building NRF24L01 Python bindings
21 December 2023
In order to fully build NRF24L01 python bindings on the Pi you will need to do this
sudo apt install -y build-essential python3-dev libboost-python-dev python3-pip python3-rpi.gpio libboost1.81-dev
git clone https://github.com/nRF24/RF24.git
cd RF24
make
sudo make install
cd RF24/pyRF24 && sudo python3 setup.py install
Error resolution
If you get error like this
arm-linux-gnueabihf-g++ -shared -Wl,-O1 -Wl,-Bsymbolic-functions -g -fwrapv -O2 -marm -march=armv6zk -mtune=arm1176jzf-s -mfpu=vfp -mfloat-abi=hard -L/usr/local/lib -I/usr/local/include -DRF24_NO_INTERRUPT build/temp.linux-armv6l-cpython-311/pyRF24.o -L/usr/lib/arm-linux-gnueabihf -lrf24 -lboost_python3 -o build/lib.linux-armv6l-cpython-311/RF24.cpython-311-arm-linux-gnueabihf.so
/usr/bin/ld: cannot find -lboost_python3: No such file or directory
collect2: error: ld returned 1 exit status
error: command '/usr/bin/arm-linux-gnueabihf-g++' failed with exit code 1
Likely cause is that name of the linked library is misplaced. For example on my DietPi system the linked library
should actually be called boost_python311. You can find out what it’s actually called by running the dpkg command e.g.
$ dpkg -L libboost-python1.81.0 | grep libboost_pyt
/usr/lib/arm-linux-gnueabihf/libboost_python311.so.1.81.0
Then you need to change this line
BOOST_LIB = "boost_python3"
to then rerun
BOOST_LIB = "boost_python311"
Ubuntu 19.10 Chromium issues after 19.04 upgrade
24 October 2019
Recently I upgraded from Ubuntu 19.04 to 19.10. Upgrade was uneventful except for Chromium losing all my saved passwords and personal HTTPS certificates. Main cause of the issue is the new chromium packaging. As of 19.10 chromium is utilizing snap packaging instead of deb. You can read the rational behind the change on the Ubuntu blog.
As a result on first invocation $HOME/.config/chromium is copied into $HOME/snap/chromium/.config/chromium.
Unfortunately that is not sufficient as you end up with a following error message
[23083:23264:1024/150717.374528:ERROR:token_service_table.cc(140)] Failed to decrypt token for service AccountId-19854958475897323
Solution is to run
snap connect chromium:password-manager-service
Thanks to this post for providing the solution..
As far as personal HTTPS certificates are concerned your best course of action is to either export those prior to the upgrade or if you don’t have that option download latest Chromium build then export the cert and reimport into your new shiny chromium :-).
If you are curious what Chromium is using for it’s config directory you can enter a following URL
chrome://version
Android 4.x TLS v1.2 built-in browser secure connection issues
09 March 2017
Recently at Fastly we have been gradually turning off TLS v1.0 and v1.1 support due to PCI mandate to deprecate them. You can read about the deprecation policy here.
We also recently received couple reports from customers about some of the Android 4.x users not being able to access some of these end points. During the investigation I found following SSLLabs issue
https://github.com/ssllabs/ssllabs-scan/issues/258
which had a pointer to this post about different vendors packaging a version of Google Chrome as their own built in browser
http://www.quirksmode.org/blog/archives/2015/02/chrome_continue.html
Unfortunately it appears that some vendors notably Samsung standardized on version of Chrome which did not have TLS v1.2 support e.g. Chrome 28. Can I Use site has a nice table of TLS v1.2 support
http://caniuse.com/#search=tls%201.2
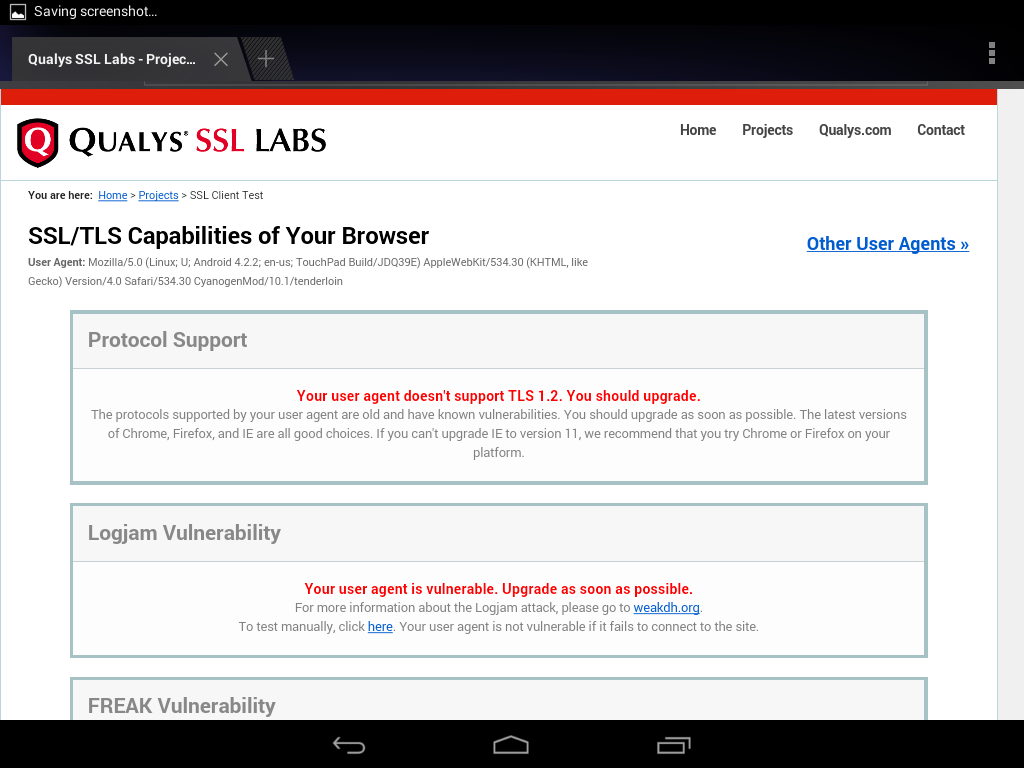
This is clearly a major hassle as it may force you to keep TLS 1.0/1.1 around for longer than you’d like or educate users to install latest Google Chrome from the Play Store. To get a better understanding what the experience may look like is I tested it on my Android 4.2 table and this is what it it looks like
This is what the built-in browser capabilities are
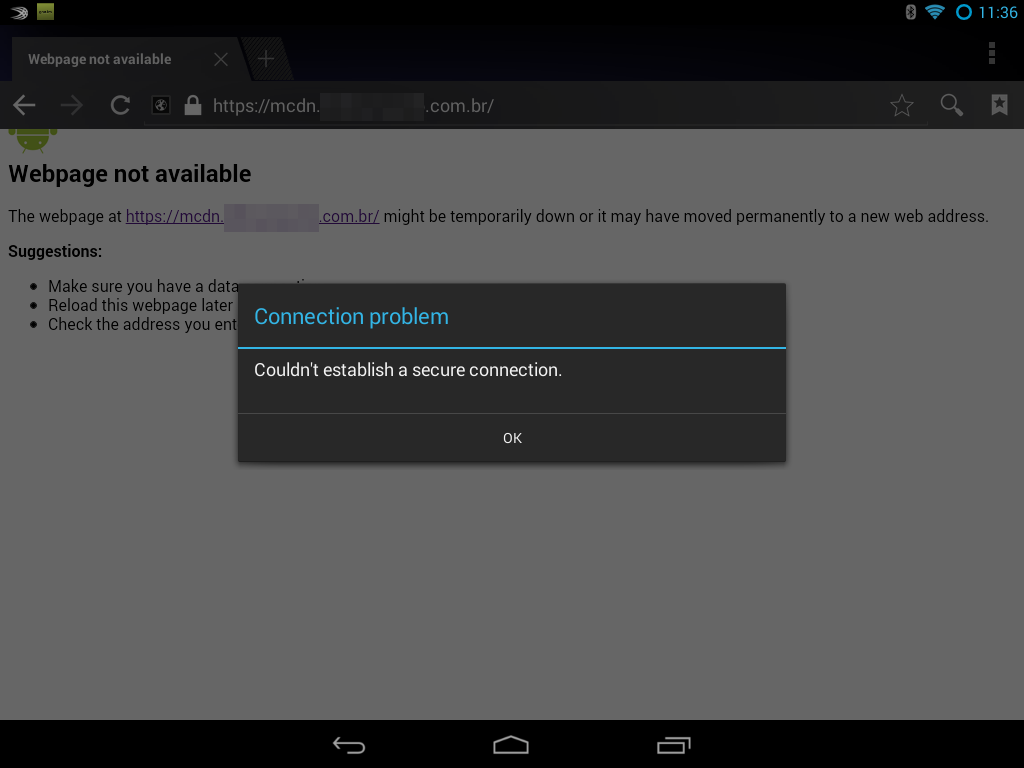
Unfortunately this will result in a very nasty error that says secure connection cannot be established
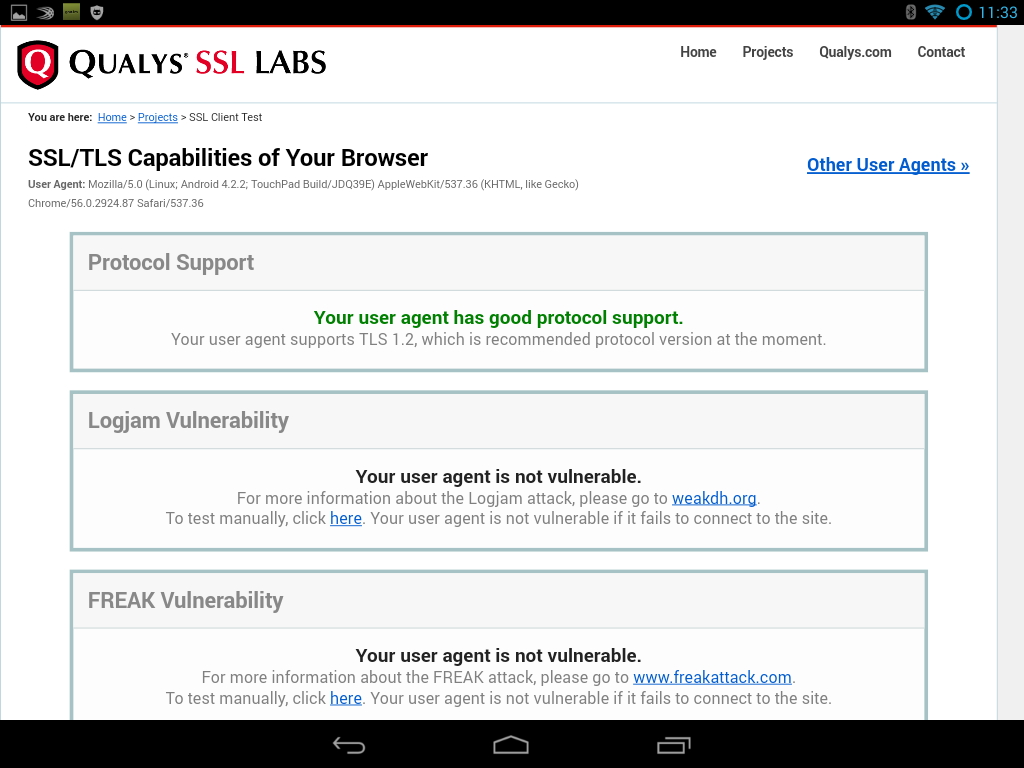
Same device with Google Chrome installed passes the capability test with flying colors
Setup Minecraft Server on Google Cloud Engine with terraform
11 May 2016
My children like to play Minecraft and they often like to play with their friends and cousins who are remote. To do so in the past I would set up my laptop at the house, set up port forwarding on the router, etc. This would often not work as the router would not accept the changes, my laptop firewall was on etc. Instead I decided to shift all this to the cloud. In this particular example I will be using Google Cloud Engine since it allows you to have persistent disks. To minimize costs I will automate creation and destruction of minecraft server(s) using Hashicorp’s Terraform.
All the terraform template and files can be found in this specific Github Repo
https://github.com/vvuksan/terraform-playground
You will need to sign up for a Google Cloud account. You may also optionally buy a domain name from a registrar so that you don’t need to enter IP addresses in your minecraft client. If you do so rename dns.tf.disabled to dns.tf and change this section
variable "domain_name" {
description = "Domain Name"
default = "change_to_the_domain_name_you_bought.xyz"
}
As described in the README what this set of templates will do is create a persistent disk where you will store your gameplay and spin up a minecraft server just for that time being. When you want to play you will need to type
make create
and when you are done playing you will type
make destroy
Cost of this should be minimal. In the TF template I’m setting a persistent disk of size of 10 GB (change that in main.tf if you need to). That will cost you approximately $0.40 per month. On top of it you’d be paying for g1.small instance cost which is about $0.02 per hour. You can certainly opt for a faster instance by adjusting the instance size in main.tf file. Also if you are using DNS there will be DNS query costs but those should be minimal.
Have fun.
- 22 Jan 2025 » Using Fastly Object Storage with DuckDB
- 21 Dec 2023 » Raspberry Pi building NRF24L01 Python bindings
- 24 Oct 2019 » Ubuntu 19.10 Chromium issues after 19.04 upgrade
- 09 Mar 2017 » Android 4.x TLS v1.2 built-in browser secure connection issues
- 11 May 2016 » Setup Minecraft Server on Google Cloud Engine with terraform
- 10 May 2016 » Rsyslog server TLS termination
- 03 May 2016 » Ganglia Web frontend in Ubuntu 16.04 install issue
- 03 May 2016 » Ganglia Web frontend in Ubuntu 16.04 install issue
- 18 Apr 2016 » Google Compute Engine Load balancer Let's Encrypt integration
- 15 Apr 2016 » Signing AWS Lambda API calls with Varnish
- 03 Apr 2015 » Howto speed up your monitoring system with Varnish
- 04 Feb 2015 » Adventures with Arduino part 2
- 31 Jan 2015 » Raspberry Pi Revision B+ NRF24L01 wiring
- 01 Jan 2015 » Adventures with Arduino part 1
- 18 May 2014 » Bosnia and Serbia Floods aid
- 07 Feb 2014 » Building your own binary packages for Cumulus Linux (PowerPC)
- 10 Jan 2014 » Running Arista vEOS under Linux KVM
- 25 Dec 2012 » Bring your own device cell service / VoIP
- 25 Nov 2012 » Mockupdata sample data creator
- 28 Sep 2012 » Monitoring health of Dell/LSI RAID arrays with Ganglia
- 01 Sep 2012 » My monitoring setup
- 20 Aug 2012 » WebOps Hackathon/(un)conference in Boston in October
- 15 Jun 2012 » Parsing JSON POST in PHP
- 22 May 2012 » PHP HTTP caching defaults
- 10 Apr 2012 » My programming language beat your honor roll language
- 06 Apr 2012 » Compute a 15 minute average of a metric easily with Ganglia
- 29 Mar 2012 » Adding context to your alerts
- 29 Mar 2012 » Monitoring NetApp Fileservers with Ganglia
- 03 Jan 2012 » RESTful way to manage your databases
- 23 Nov 2011 » Operating on Dell RAID arrays cheatsheet
- 27 Sep 2011 » Use fantomTest to test web pages from multiple locations
- 22 Aug 2011 » Using Jenkins as a Cron Server
- 02 Aug 2011 » Testing your web pages with fantomtest
- 06 Jun 2011 » Monitoring links and monitoring anti-patterns video
- 19 Apr 2011 » Use your trending data for alerting
- 21 Feb 2011 » JSON representation for graphs in Ganglia
- 14 Dec 2010 » Misconceptions about RRD storage
- 11 Dec 2010 » Rethinking Ganglia Web UI
- 29 Sep 2010 » Integrating Graphite with Ganglia
- 09 Sep 2010 » EC2 micro instances cost analysis
- 01 Sep 2010 » Install Openstack Nova easily using Chef and Nova-Solo
- 26 Aug 2010 » Slides from the Boston DevOps meetup
- 20 Aug 2010 » Tunnel all your traffic on "hostile" networks with OpenVPN
- 19 Aug 2010 » Skipping MySQL replication errors
- 16 Aug 2010 » PHP 5.3 name spaces separator
- 12 Aug 2010 » Deployment rollback
- 29 Jul 2010 » Bootstraping your cloud environment with puppet and mcollective
- 21 Jul 2010 » Next Boston DevOps meetup
- 20 Jul 2010 » Provision to cloud in 5 minutes using fog
- 16 Jul 2010 » Analyzing your backend web page response times
- 15 Jul 2010 » CouchDB views creation problems
- 06 Jul 2010 » Store your cron output for analysis and correlation with cronologger
- 28 Jun 2010 » Overlay deploy timeline on Ganglia graphs
- 27 Jun 2010 » Velocity Conference 2010 takeaways
- 16 Jun 2010 » GangliaView – automatically rotate Ganglia metrics
- 16 Jun 2010 » Non-Dell SSDs/drives not supported until Q2 2011
- 05 Jun 2010 » Beauty of aggregate line graphs
- 27 May 2010 » Devops homebrew part deux
- 13 May 2010 » Vonage the new Baby Bell
- 11 May 2010 » Installing RedHat 6 Enterprise DomU under Xen
- 28 Apr 2010 » Customizing iomega StorCenter ix4-200d with ipkg
- 21 Apr 2010 » Tracking web clients in real time
- 09 Apr 2010 » Devops homebrew
- 06 Apr 2010 » Devops religion wars
- 11 Mar 2010 » Building Redhat/CentOS KVM images on Ubuntu 9.10
- 22 Jan 2010 » Password complexity madness
- 20 Jan 2010 » Cool DNS tricks you can't use for fail-overs
- 15 Jan 2010 » Monitoring your website performance via 90th percentile response time
- 01 Dec 2009 » Quick way to determine SSL certificate expiration
- 05 Nov 2009 » Don't let mySQL substitute engines
- 06 Oct 2009 » Infrastructure redundancy is not cheap
- 02 Oct 2009 » Keeping an eye on binary log growth
- 14 Sep 2009 » Nagios alerts based on Ganglia metrics
- 13 Sep 2009 » Software doesn't run itself
- 11 Sep 2009 » Simple "web service" for Ganglia metrics
- 09 Sep 2009 » Broken hostname resolution and PAM don't mix
- 27 Aug 2009 » Howto install a SSL certificate with intermediate certificate on a Cisco load balancer